ORM模型
对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。
ORM 在业务逻辑层和数据库层之间充当了桥梁的作用,解决的是对象和关系的映射
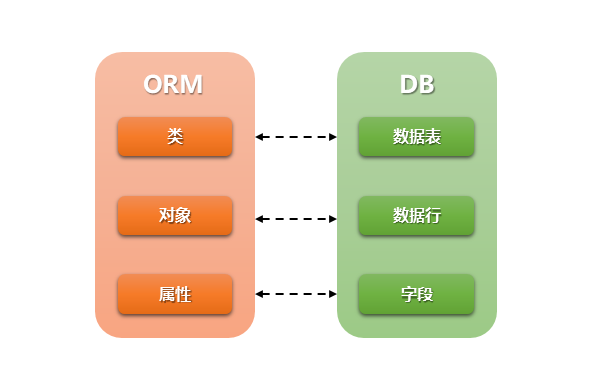
ORM的缺点是会在一定程度上牺牲程序的执行效率,以及不适用于复杂的查询场景。
Django中内置的ORM模型
想要在Djaogo中使用ORM模型,首先要在seethings配置文件中指定后端的数据库引擎,默认是SQLite3,
我们可以修改其为MySQL。
1
2
3
4
5
6
7
8
9
10
| DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'django_db',
'HOST': '127.0.0.1',
'PORT': 3306,
'USER': 'root',
'PASSWORD': '123456'
}
}
|
1
2
3
4
5
|
import pymysql
pymysql.install_as_MySQLdb()
|
在Django中每创建一个应用,其应用下都会有一个models.py文件,我们可以将应用的模型类写入到这个文件里
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
from django.db import models
class Book(models.Model):
title = models.CharField(max_length=32)
publish_date = models.DateField(auto_now_add=True)
price = models.DecimalField(max_digits=5, decimal_places=2)
memo = models.TextField(null=True)
publisher = models.ForeignKey(to="Publisher")
author = models.ManyToManyField(to="Author")
def __str__(self):
return "<Book object: {} {}>".format(self.id, self.title)
class Meta:
db_table = 'book'
class Publisher(models.Model):
name = models.CharField(max_length=32)
city = models.CharField(max_length=32)
def __str__(self):
return "<Publisher object: {} {}>".format(self.id, self.name)
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
phone = models.CharField(max_length=11)
def __str__(self):
return "<Author object: {} {}>".format(self.id, self.name)
|
最后执行迁移命令,将模型类做迁移映射至MySQL数据库中
1
2
| python manage.py makemigrations
python manage.py migrate
|
在django的源码中可以看到,模型中定义的像CharField,IntegerField都会与MySQL数据库的字段类型一一映射

Django 中常用的 Field types
AutoField:int 自增列,必须填入参数 primary_key=True。当 model 中如果没有自增列,则自动会创建一个列名为 id 的列;
BooleanField:布尔类型 (True/False),这个Field不接受null参数,要想使用可以为 null 的布尔类型的字段,就要使用 NullBooleanField;
CharField:最常用的字段类,映射到数据库中会转换成 varchar 类型,使用时必须传入 max_length 属性以定义该字符串的最大长度,如果超过254个字符,就不建议使用 CharField 了,此时建议使用 TextField;
DateField 和 DateTimeField:都是日期时间的字段类,注意前者只到天,后者可以精确到毫秒。使用这两个 Field 可以传递以下几个参数:
- auto_now=True:在每次这个数据保存的时候,都使用当前的时间;
- auto_now_add=True:在每条数据第一次被添加进去的时候,都使用当前的时间;
此外要注意的是 auto_add_now,auto_now 与 default 是互斥的。
DecimalField:处理浮点类型的 Field。从上面的源码可以看到,它有两个必须填入的参数:
- max_digits:数字允许的最大位数;
- decimal_places:小数的最大位数;
FloatField:也是处理浮点类型的 Field。它和 DecimalField 的区别就是 Python 中 float 和 decimal 的区别;
IntegerField /BigIntegerField/SmallIntegerField:都是处理整数类型的 Field;
TextField:长文本类型 Field,对应 MySQL 中的 longtext 类型。
Django 中 Field 选项
每种 Field 类会有一些特定的 Field 选项,比如 CharField 必须要传入 max_length 属性值。但是下面这些属性对于所有 Field 类都是有效的:
- null:默认为 False。如果为 True 则表明在数据库中该字段可以为 null;
- blank:默认为 False。如果为 True 则表明在数据库中该字段可以为不填;
- choice:设置可选项,表明该字段的值只能从 choice 中选择
- default:设置字段的默认值;
- help_text:设置说明信息;
- primary_key:如果为 True,表明设置该字段为主键。此时 Django 便不会再为我们添加默认的 id 主键了;
- unique:设置该字段的值在表中唯一。
Django使用ORM进行增查改删
单表操作
1.增加
1
2
3
4
5
|
book_obj = models.Book(title='老人与海', publish_date='2020-02-02', price=60, publisher_id=1)
book_obj.save()
models.Book.objects.create(title='百年孤独', publish_date='2020-02-02', price=50, publisher_id=1)
|
2.查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
book_obj = models.Book.objects.all()
print(book_obj)
print(models.Book.objects.filter(title="老人与海"))
print(models.Book.objects.filter(title="老人与海",price=60))
print(models.Book.objects.get(title="老人与海"))
print( models.Book.objects.exclude(title="老人与海"))
print(models.Book.objects.filter(title="老人与海").values("id","price"))
print(models.Book.objects.filter(title="老人与海").values_list("id","price"))
print(models.Book.objects.all().order_by("price"))
print(models.Book.objects.all().order_by("-price"))
print(models.Book.objects.all().reverse())
print(models.Book.objects.filter(title="老人与海").values("price").distinct())
print(models.Book.objects.filter(title="老人与海").count())
|
如果上述这些方法的返回结果是一个 QuerySet 实例,那么它也同样具有上面这些方法,因此可以继续调用,形成链式调用
其他
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| 方法名 解释
annotate() 使用聚合函数
dates() 根据日期获取查询集
datetimes() 根据时间获取查询集
none() 创建空的查询集
union() 并集
intersection() 交集
difference() 差集
select_related() 附带查询关联对象
prefetch_related() 预先查询
extra() 附加SQL查询
defer() 不加载指定字段
only() 只加载指定的字段
using() 选择数据库
select_for_update() 锁住选择的对象,直到事务结束。
raw() 接收一个原始的SQL查询
bulk_create([]) 批量添加
|
在 filter() 方法中还有一些比较神奇的双下划线辅助我们进一步过滤结果
1
2
3
4
5
6
7
8
9
10
11
12
13
| 字段名__gt
字段名__gte
字段名__lt
字段名__lte
字段名__range=[1,3]
字段名__in=[1,3]
字段名__contains=''
字段名__icontains=''
字段名__startswith=''
字段名__istartswith=''
字段名__endswith=''
字段名__iendswith=''
字段名__isnull=True
|
F查询和Q查询
上面构造的过滤器都只是将字段值与某个常量做比较,如果要对两个字段的值做比较,就需要使用 F查询。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值:
1
2
3
4
5
| from django.db.models import F,Q
print(models.Book.objects.all().filter(id__gt=F('price')/10))
print(models.Book.objects.all().update(price=F('price')-5))
|
上面的多个 filter() 方法实现的是过滤条件的 “AND” 操作,如果想实现过滤条件 “OR” 操作,就需要使用Q查询:
1
2
3
4
|
print(models.Book.objects.filter(Q(publish_date__year=2020)|Q(price__gt=50)))
print(models.Book.objects.filter(~Q(publish_date__year=2020)&Q(price__gt=5)))
|
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将”AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。
3.修改
1
2
3
4
5
6
7
|
book = models.Book.objects.get(id=1)
book.title = '三体'
book.save()
print(models.Book.objects.all().update(price=F('price')-5))
|
4.删除
1
2
3
4
| models.Book.objects.filter(publish_date__year=2020).delete()
book = models.Book.objects.get(id=1)
book.delete()
|
跨表操作
1.外键
外键 (Foreign Key)是用于建立和加强两个表数据之间的链接的一列或多列,使两张表形成关联,就是当你对一个表的数据进行操作,和他有关联的一个或更多表的数据能够同时发生改变。
在 MySQL 种想使用外键需要具备一定条件:
- MySQL 重需要关联的表必须都使用 InnoDB 引擎创建,MyISAM 表暂时不支持外键;
- 外键列必须建立了索引,MySQL 4.1.2 以后的版本在建立外键时会自动创建索引,但如果在较早的版本则需要显式建立;
- 外键关系的两个表的列必须是数据类型相似,也就是可以相互转换类型的列,比如 int 和 tinyint 可以,而 int和char 则不可以。
前面在定义外键时,我们添加了一个 on_delete 属性,这个属性控制着在删除子表外键连接的记录时,对应字表的记录会如何处理,它有如下属性值:
CASCADE:级联操作。如果外键对应的那条记录被删除了,那么子表中所有外键为那个记录的数据都会被删除。
PROTECT:受保护。即只要子表中有记录引用了外键的那条记录,那么就不能删除外键的那条记录。如果我们强行删除,Django 就会报 ProtectedError 异常
SET_NULL:设置为空。如果外键的那条数据被删除了,那么子表中所有外键为该条记录的对应字段值会被设置为 NULL,前提是要指定这个字段可以为空,否则也会报错
SET_DEFAULT:设置默认值。和上面类似,前提是字表的这个字段有默认值
DO_NOTHING:什么也不做,一切全看数据库级别的约束。在 MySQL 中,这种情况下无法执行删除动作
1
2
|
publisher = models.ForeignKey(to="Publisher")
|
2.表关系
一对一的关系:OneToOne(“要绑定关系的表名”)
一对多的关系:ForeignKey(“要绑定关系的表名”)
多对多的关系:ManyToMany(“要绑定关系的表名”) 会自动创建第三张表
一对多添加记录
1
2
3
4
5
6
7
8
9
10
11
12
|
models.Book.objects.create(title="追风筝的人",publish_date="2015-5-8",price="111",publisher_id=1)
pub_obj = models.Publisher.objects.filter(name="人民出版社")[0]
print(pub_obj)
models.Book.objects.create(title = "钢铁是怎样炼成的",publish_date="1996-6-6",price="66",publisher=pub_obj)
pub_obj= models.Publisher.objects.get(name="人民出版社")
book_obj = models.Book(title = "看见",publish_date="2014-11-24",price="50",publisher=pub_obj)
book_obj.save()
|
多对多添加记录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
pub_obj=models.Publisher.objects.filter(name="人民出版社").first()
book_obj = models.Book.objects.create(title="原则",publish_date="2020-02-02",price="80", publisher=pub_obj)
zhangsan_obj = models.Author.objects.filter(name="zhangsan")[0]
lisi_obj = models.Author.objects.filter(name="lisi")[0]
zhan_obj = models.Author.objects.filter(name="zhan")[0]
book_obj.author.add(zhangsan_obj, lisi_obj, zhan_obj)
pub_obj = models.Publisher.objects.filter(name="人民出版社").first()
book_obj = models.Book.objects.create(title="原则", publish_date="2020-02-02",price="80", publisher=pub_obj)
authers = models.Author.objects.all()
book_obj.author.add(*authers)
book_obj.author.remove(*authers)
book_obj.author.clear(*authers)
|
3.跨表查询
一对多查询记录:
正向查询(按字段:publisher):
反向查询(按表名:book_set):
1
2
3
4
5
6
7
8
9
|
book_obj = models.Book.objects.filter(title="老人与海")[0]
print("出版社对象", book_obj.publisher)
print(book_obj.publisher.city)
pub_obj = models.Publish.objects.filter(name="人民出版社")[0]
book_dic = pub_obj.book_set.all().values("price", "title")[0]
print(book_dic)
print(book_dic["price"])
|
多对多查询记录:
正向查询(按字段author)
反向查询(按表名book_set)
1
2
3
4
5
6
|
book_obj = models.Book.objects.filter(title="老人与海")[0]
print(book_obj.author.all().values("name", "age"))
zhangsan_obj = models.Author.objects.filter(name="zhangsan")[0]
print("books:", zhangsan_obj.book_set.all())
|
可以通过在 ForeignKey() 和ManyToManyField的定义中设置 related_name 的值来覆写 xxx_set 的名称。
注:多对多的查询用.all,查单个的时候用.values或者values_list,不要用obj.Author.name,,这样查到的会是None,反向查询也是如此。不管是一对多,还是多对多,要是查询多得一方就得用all()
基于双下划线的跨表查询
Django 还提供了一种直观而高效的方式在查询中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的 model 为止。相当于用sql语句用join连接的方式
双下划线一对多查询
1
2
3
4
|
ret = models.Publisher.objects.filter(name="人民出版社").values("book__price","book__title")
ret2 = models.Book.objects.filter(publisher__name="人民出版社").values("price","title")
|
双下划线多对多查询
1
2
3
4
|
ret = models.Author.objects.filter(name="zhan").values("book__title")
ret2 = models.Book.objects.filter(author__name="zhan").values("title")
|
聚合查询与分组查询

聚合查询:aggregate(*args, **kwargs),只对一个组进行聚合
它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。
1
2
3
| from django.db.models import Avg,Sum,Count,Max,Min
print(models.Book.objects.all().aggregate(平均价格=Avg("price")))
|
分组查询 :annotate(*args, **kwargs):先分组然后再进行某些聚合操作或排序
它返回结果的不仅仅是含有统计结果的一个字典,而是包含有新增统计字段的查询集 (QuerySet)
1
2
3
| from django.db.models import Avg,Sum,Count,Max,Min
print(models.Book.objects.values("author__name").annotate(authorsNum=Count("author__name")).order_by("authorsNum"))
|
- annotate 方法前面的 values 中出现的字段正是需要 GROUP BY 的字段。values 方法中出现多个值,即对多个字段进行 GROUP BY;
- annotate 方法的结果是一个查询集 (QuerySet),这样我们可以继续在后面调用 filter()、order_by() 等方法进行进一步过滤结果;
- order_by 方法是对前面的 QuerySet 按某些字段排序,类似于 SQL 中的 ORDER BY 操作。排序字段前面加上 “-” 表示按倒序顺序,类似于 DESC 操作

