一. RabbitMQ 简介
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。
二. RabbitMQ 使用场景
1. 解耦(为面向服务的架构(SOA)提供基本的最终一致性实现)
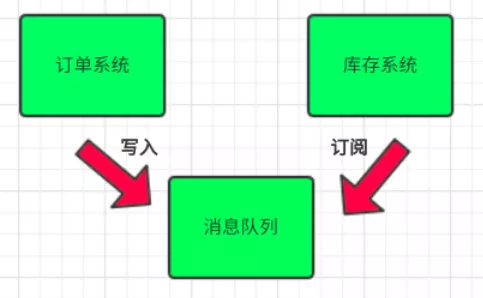
传统模式的缺点:
- 假如库存系统无法访问,则订单减库存将失败,从而导致订单失败
- 订单系统与库存系统耦合
引入消息队列
- 订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功
- 库存系统:订阅下单的消息,采用拉/推的方式,获取下单信息,库存系统根据下单信息,进行库存操作
- 假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦
- 为了保证库存肯定有,可以将队列大小设置成库存数量,或者采用其他方式解决。
2. 异步提升效率
场景说明:用户注册后,需要发注册邮件和注册短信。传统的做法有两种 1.串行的方式;2.并行方式
(1)串行方式:将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端
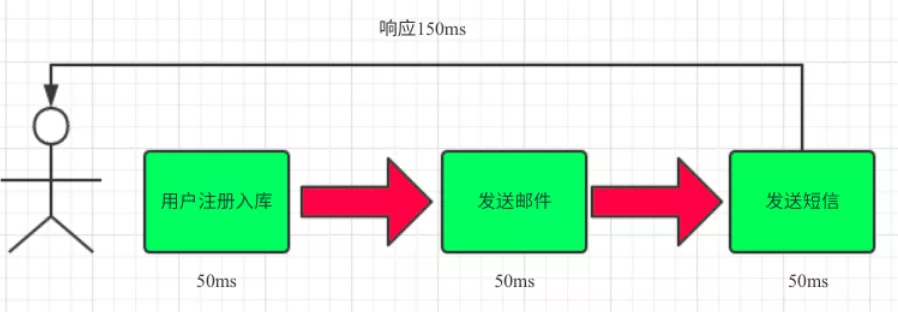
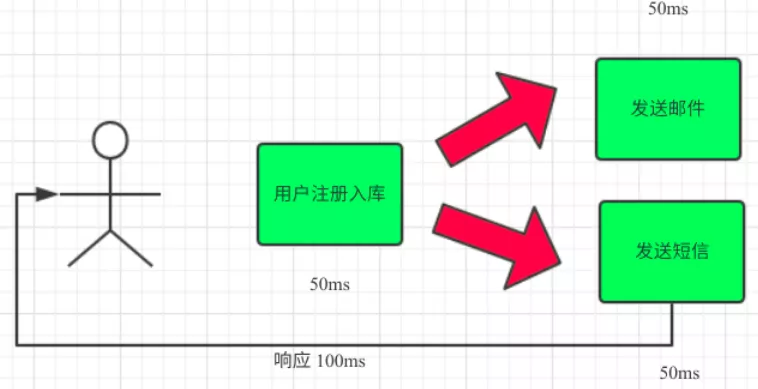
(2)并行方式:将注册信息写入数据库成功后,发送注册邮件的同时,发送注册短信。以上三个任务完成后,返回给客户端。与串行的差别是,并行的方式可以提高处理的时间
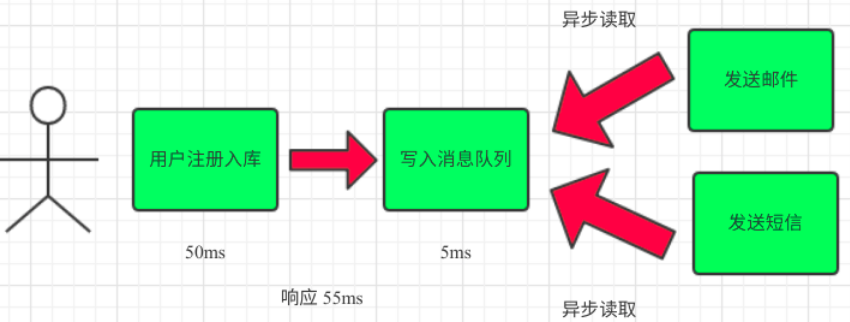
引入消息队列,将不是必须的业务逻辑,异步处理。改造后的架构如下:
3. 流量削峰
流量削峰也是消息队列中的常用场景,一般在秒杀或团抢活动中使用广泛
应用场景:系统其他时间A系统每秒请求量就100个,系统可以稳定运行。系统每天晚间八点有秒杀活动,每秒并发请求量增至1万条,但是系统最大的处理能力只能每秒处理1000个请求,于是系统崩溃,服务器宕机。
之前架构:大量用户(100万用户)通过浏览器在晚上八点高峰期同时参与秒杀活动。大量的请求涌入我们的系统中,高峰期达到每秒钟5000个请求,大量的请求打到MySQL上,每秒钟预计执行3000条SQL。但是一般的MySQL每秒钟扛住2000个请求就不错了,如果达到3000个请求的话可能MySQL直接就瘫痪了,从而系统无法被使用。但是高峰期过了之后,就成了低峰期,可能也就1万用户访问系统,每秒的请求数量也就50个左右,整个系统几乎没有任何压力。
引入MQ:100万用户在高峰期的时候,每秒请求有5000个请求左右,将这5000请求写入MQ里面,系统A每秒最多只能处理2000请求,因为MySQL每秒只能处理2000个请求。系统A从MQ中慢慢拉取请求,每秒就拉取2000个请求,不要超过自己每秒能处理的请求数量即可。MQ,每秒5000个请求进来,结果只有2000个请求出去,所以在秒杀期间(将近一小时)可能会有几十万或者几百万的请求积压在MQ中。
关于流量削峰:秒杀系统流量削峰这事儿应该怎么做?
这个短暂的高峰期积压是没问题的,因为高峰期过了之后,每秒就只有50个请求进入MQ了,但是系统还是按照每秒2000个请求的速度在处理,所以说,只要高峰期一过,系统就会快速将积压的消息消费掉。我们在此计算一下,每秒在MQ积压3000条消息,1分钟会积压18万,1小时积压1000万条消息,高峰期过后,1个多小时就可以将积压的1000万消息消费掉。

三. 引入消息队列的优缺点
优点
优点就是以上的那些场景应用,就是在特殊场景下有其对应的好处,解耦、异步、削峰。
缺点
系统引入的外部依赖越多,系统越容易挂掉,本来只是A系统调用BCD三个系统接口就好,ABCD四个系统不报错整个系统会正常运行。引入了MQ之后,虽然ABCD系统没出错,但MQ挂了以后,整个系统也会崩溃。
引入了MQ之后,需要考虑的问题也变得多了,如何保证消息没有重复消费?如何保证消息不丢失?怎么保证消息传递的顺序?
A系统发送完消息直接返回成功,但是BCD系统之中若有系统写库失败,则会产生数据不一致的问题。
解决
系统的可用性降低
做MQ集群
对于复杂性问题
- 1.如果消息是做数据库的插入操作,给这个消息做一个唯一主键,那么就算出现重复消费的情况,就会导致主键冲突,避免数据库出现脏数据。
- 如果你拿到这个消息做redis的set的操作,不用解决,因为你无论set几次结果都是一样的,set操作本来就算幂等操作。
- 3.如果上面两种情况还不行,准备一个第三服务方来做消费记录。以redis为例,给消息分配一个全局id,只要消费过该消息,将<id,message>以K-V形式写入redis。那消费者开始消费前,先去redis中查询有没消费记录即可。
- 对于可靠性:可以做持久化,采用了手动确认消息模式
如何解决消息队列的延时以及过期失效问题?有几百万消息持续积压几小时,怎么解决?
消息队列的延迟和过期失效是消息队列的自我保护机制,目的是为了防止本身被挤爆,当然是可以关闭保护,比如当某个消息消费失败5次后,就把这个消息丢弃等,尽量不要关掉保护机制
那些被丢弃的消息,我们可以针对该业务,查询出来将丢失的那批数据,写个临时程序,一点一点的查出来,然后重新放入mq中,把丢的数据找回。
四. 消息队列代码实例
1. 简单模式
send.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='myqueue1', durable=True)
channel.basic_publish(exchange='',
routing_key='myqueue1',
body='hello world',
properties=pika.BasicProperties(
delivery_mode=2,
))
print("消息发送完成!")
connection.close()
|
receive.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='myqueue1', durable=True)
channel.basic_qos(prefetch_count=1)
def callback(ch, method, properties, body):
ch.basic_ack(delivery_tag=method.delivery_tag)
print(f"收到消息:{body}")
channel.basic_consume(queue='myqueue1',
auto_ack=False,
on_message_callback=callback)
channel.start_consuming()
|
2.交换机模式
exchange_send.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
exchange_type='fanout')
channel.basic_publish(exchange='logs',
routing_key='',
body='hello logs',
)
print("消息发送完成!")
connection.close()
|
exchange_recv.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
exchange_type='fanout')
result = channel.queue_declare("", exclusive=True)
queue_name = result.method.queue
def callback(ch, method, properties, body):
ch.basic_ack(delivery_tag=method.delivery_tag)
print(f"收到消息:{body}")
channel.queue_bind(exchange='logs',
queue=queue_name)
channel.basic_consume(queue=queue_name,
auto_ack=False,
on_message_callback=callback)
channel.start_consuming()
|
3.关键字模式
direct_send.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs2',
exchange_type='direct')
channel.basic_publish(exchange='logs2',
routing_key='info',
body='hello logs',
)
print("消息发送完成!")
connection.close()
|
direct_recv.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs2',
exchange_type='direct')
result = channel.queue_declare("", exclusive=True)
queue_name = result.method.queue
def callback(ch, method, properties, body):
ch.basic_ack(delivery_tag=method.delivery_tag)
print(f"收到消息:{body}")
channel.queue_bind(exchange='logs2',
queue=queue_name,
routing_key='info')
channel.basic_consume(queue=queue_name,
auto_ack=False,
on_message_callback=callback)
channel.start_consuming()
|
4.通配符模式
re_send.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs3',
exchange_type='topic')
channel.basic_publish(exchange='logs3',
routing_key='info.123',
body='[info]: info.123',
)
print("消息发送完成!")
connection.close()
|
re.recv.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs3',
exchange_type='topic')
result = channel.queue_declare("", exclusive=True)
queue_name = result.method.queue
def callback(ch, method, properties, body):
ch.basic_ack(delivery_tag=method.delivery_tag)
print(f"收到消息:{body}")
channel.queue_bind(exchange='logs3',
queue=queue_name,
routing_key='#.123')
channel.basic_consume(queue=queue_name,
auto_ack=False,
on_message_callback=callback)
channel.start_consuming()
|

